 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation Steering for Synthetic Data Generation: The Role of Diversity in Downstream Safety Detection
May 27, 2026Safety detection models require examples of HHH (Helpful, Harmless, Honest)-violating outputs for robust generalization, however such examples are scarce. Activation Steering (AS) has emerged as a data-efficient method for generating target-concept-aligned responses. We investigate whether AS can generate high-quality training datasets for downstream classifiers, a question that remains untested. We present a two-fold study with intrinsic and extrinsic evaluation across $4$ concepts $\times\,2$ models $\times\,4$ steering methods. Intrinsically, beyond the field-standard rubric of steering success (concept alignment) and coherence, we introduce sample- and set-level diversity as a quality axis previously absent from the literature, and find that increasing steering strength reduces response diversity. Extrinsically, we replace HHH-violating examples in the available training data with steered generations and fine-tune detection classifiers. AS-generated data results in a better classifier than the prompting-generated data on $3$ of $4$ concepts. However, only $41$ of $136$ AS configurations outperform prompting, indicating that downstream utility lies in a narrow regime that jointly satisfies success, coherence, and diversity. The harmonic mean of these three axes correlates with downstream AUROC more consistently across concepts than success and coherence alone, providing a practical heuristic target for practitioners tuning AS hyperparameters. Together, our results highlight the potential of AS in synthetic data generation for improving safety detection and identify diversity as a critical, previously overlooked axis for tuning AS.
Structured Prompt Optimization Meets Reinforcement Learning for Global and Local Interpretability over Complex Text
May 27, 2026LLMs have advanced text classification, yet existing paradigms face a trade-off: supervised (label only) fine-tuning is scalable but offers limited reasoning on complex text and lacks broader model transparency, while discrete prompt optimization offers human-readable instructions but struggles with performance and scalability. We introduce eXTC (eXplainable Text Classifier) with three progressive stages: (1) learning a Standard Operating Procedure (SOP, or rulebook) in natural language via a new Structured Prompt Optimization algorithm; (2) SOP-grounded reasoning distillation from a large teacher LLM into a compact LM; and (3) expanding reasoning capabilities beyond the initial SOP via reinforcement learning. This design enables eXTC to provide (i) fast inference via a compact LM, with (ii) inference-time local reasoning traces, alongside a global, modular explanation of its learned domain rules, while (iii) significantly outperforming existing paradigms across diverse benchmarks in both classification performance and explanation quality, with stage-by-stage gains.
VIP-COP: Context Optimization for Tabular Foundation Models
May 13, 2026Tabular foundation models (TFMs) have emerged as a powerful paradigm for in-context learning on structured data, enabling direct prediction on new tabular tasks without task-specific training. However, their effectiveness is constrained by context length limits, restricting application to medium-scale data and degrading performance when inference-time data exceed pretraining size distributions. Our work introduces VIP-COP, estimating the Value of Importance for Prediction of training examples and features for hard Context OPtimization for TFMs. Its explicit selection mechanism suppresses noise and isolates influential data, enabling the model to also benefit from data augmentation by prioritizing high-value augmented samples and features. VIP-COP is (i) fast, boosting performance often within minutes of optimization, based on an online KernelSHAP-based regression with iterative refinement, value-guided context sampling, and multi-fidelity pruning; (ii) budget-aware and any-time, improving with additional test-time compute unlike heuristics that produce fixed contexts; (iii) model-aware yet fully black-box, requiring no access to model internals, making it compatible with both proprietary and open-source TFMs; (iv) interpretable, identifying discrete ``Very Important Predictors'' (samples and features) that maximize signal-to-noise, which makes it (v) robust, isolating high-value data from noise. In contrast, soft-prompt optimization requires model gradients, produces abstract latent tokens, and lacks explicit signal discrimination. Extensive experiments show that VIP-COP consistently outperforms heuristic and optimized baselines across large-scale high-dimensional testbeds, including data augmentation and data-noise settings, establishing a new state of the art in test-time context refinement for TFMs.
Long-Horizon Plan Execution in Large Tool Spaces through Entropy-Guided Branching
Apr 13, 2026Large Language Models (LLMs) have significantly advanced tool-augmented agents, enabling autonomous reasoning via API interactions. However, executing multi-step tasks within massive tool libraries remains challenging due to two critical bottlenecks: (1) the absence of rigorous, plan-level evaluation frameworks and (2) the computational demand of exploring vast decision spaces stemming from large toolsets and long-horizon planning. To bridge these gaps, we first introduce SLATE (Synthetic Large-scale API Toolkit for E-commerce), a large-scale context-aware benchmark designed for the automated assessment of tool-integrated agents. Unlike static metrics, SLATE accommodates diverse yet functionally valid execution trajectories, revealing that current agents struggle with self-correction and search efficiency. Motivated by these findings, we next propose Entropy-Guided Branching (EGB), an uncertainty-aware search algorithm that dynamically expands decision branches where predictive entropy is high. EGB optimizes the exploration-exploitation trade-off, significantly enhancing both task success rates and computational efficiency. Extensive experiments on SLATE demonstrate that our dual contribution provides a robust foundation for developing reliable and scalable LLM agents in tool-rich environments.
MacrOData: New Benchmarks of Thousands of Datasets for Tabular Outlier Detection
Feb 10, 2026Quality benchmarks are essential for fairly and accurately tracking scientific progress and enabling practitioners to make informed methodological choices. Outlier detection (OD) on tabular data underpins numerous real-world applications, yet existing OD benchmarks remain limited. The prominent OD benchmark AdBench is the de facto standard in the literature, yet comprises only 57 datasets. In addition to other shortcomings discussed in this work, its small scale severely restricts diversity and statistical power. We introduce MacrOData, a large-scale benchmark suite for tabular OD comprising three carefully curated components: OddBench, with 790 datasets containing real-world semantic anomalies; OvrBench, with 856 datasets featuring real-world statistical outliers; and SynBench, with 800 synthetically generated datasets spanning diverse data priors and outlier archetypes. Owing to its scale and diversity, MacrOData enables comprehensive and statistically robust evaluation of tabular OD methods. Our benchmarks further satisfy several key desiderata: We provide standardized train/test splits for all datasets, public/private benchmark partitions with held-out test labels for the latter reserved toward an online leaderboard, and annotate our datasets with semantic metadata. We conduct extensive experiments across all benchmarks, evaluating a broad range of OD methods comprising classical, deep, and foundation models, over diverse hyperparameter configurations. We report detailed empirical findings, practical guidelines, as well as individual performances as references for future research. All benchmarks containing 2,446 datasets combined are open-sourced, along with a publicly accessible leaderboard hosted at https://huggingface.co/MacrOData-CMU.
From Zero to Hero: Advancing Zero-Shot Foundation Models for Tabular Outlier Detection
Feb 03, 2026Outlier detection (OD) is widely used in practice; but its effective deployment on new tasks is hindered by lack of labeled outliers, which makes algorithm and hyperparameter selection notoriously hard. Foundation models (FMs) have transformed ML, and OD is no exception: Shen et. al. (2025) introduced FoMo-0D, the first FM for OD, achieving remarkable performance against numerous baselines. This work introduces OUTFORMER, which advances FoMo-0D with (1) a mixture of synthetic priors and (2) self-evolving curriculum training. OUTFORMER is pretrained solely on synthetic labeled datasets and infers test labels of a new task by using its training data as in-context input. Inference is fast and zero-shot, requiring merely forward pass and no labeled outliers. Thanks to in-context learning, it requires zero additional work-no OD model training or bespoke model selection-enabling truly plug-and-play deployment. OUTFORMER achieves state-of-the-art performance on the prominent AdBench, as well as two new large-scale OD benchmarks that we introduce, comprising over 1,500 datasets, while maintaining speedy inference.
Hierarchical Token Prepending: Enhancing Information Flow in Decoder-based LLM Embeddings
Nov 18, 2025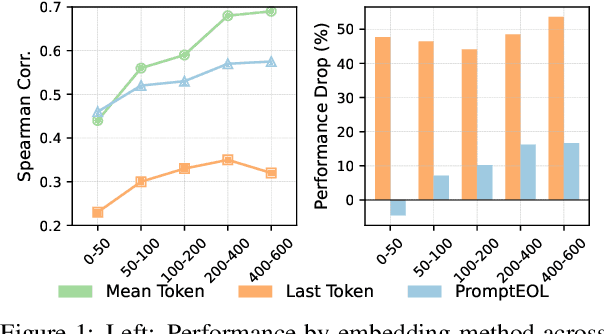
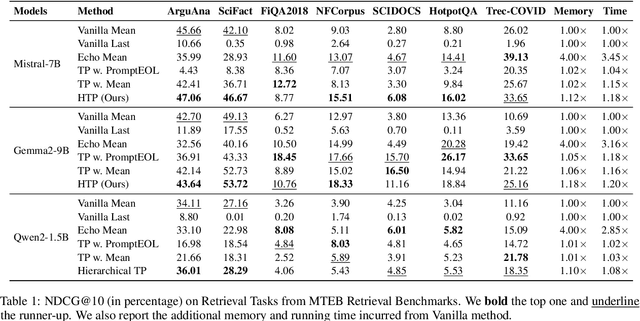
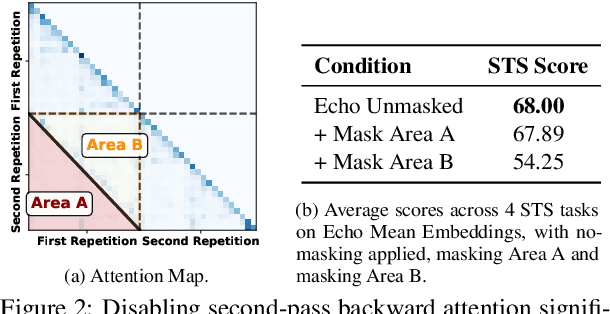
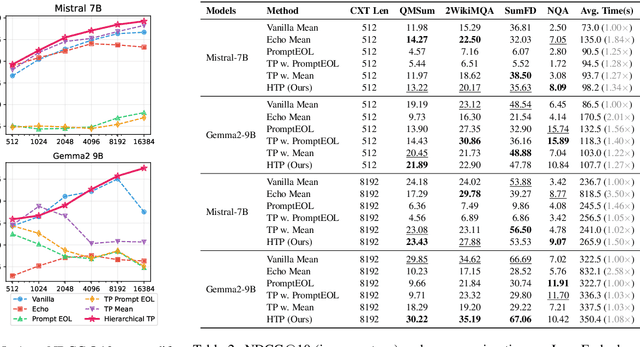
Large language models produce powerful text embeddings, but their causal attention mechanism restricts the flow of information from later to earlier tokens, degrading representation quality. While recent methods attempt to solve this by prepending a single summary token, they over-compress information, hence harming performance on long documents. We propose Hierarchical Token Prepending (HTP), a method that resolves two critical bottlenecks. To mitigate attention-level compression, HTP partitions the input into blocks and prepends block-level summary tokens to subsequent blocks, creating multiple pathways for backward information flow. To address readout-level over-squashing, we replace last-token pooling with mean-pooling, a choice supported by theoretical analysis. HTP achieves consistent performance gains across 11 retrieval datasets and 30 general embedding benchmarks, especially in long-context settings. As a simple, architecture-agnostic method, HTP enhances both zero-shot and finetuned models, offering a scalable route to superior long-document embeddings.
Uncertainty-aware Human Mobility Modeling and Anomaly Detection
Oct 02, 2024Given the GPS coordinates of a large collection of human agents over time, how can we model their mobility behavior toward effective anomaly detection (e.g. for bad-actor or malicious behavior detection) without any labeled data? Human mobility and trajectory modeling have been studied extensively with varying capacity to handle complex input, and performance-efficiency trade-offs. With the arrival of more expressive models in machine learning, we attempt to model GPS data as a sequence of stay-point events, each with a set of characterizing spatiotemporal features, and leverage modern sequence models such as Transformers for un/self-supervised training and inference. Notably, driven by the inherent stochasticity of certain individuals' behavior, we equip our model with aleatoric/data uncertainty estimation. In addition, to handle data sparsity of a large variety of behaviors, we incorporate epistemic/model uncertainty into our model. Together, aleatoric and epistemic uncertainty enable a robust loss and training dynamics, as well as uncertainty-aware decision making in anomaly scoring. Experiments on large expert-simulated datasets with tens of thousands of agents demonstrate the effectiveness of our model against both forecasting and anomaly detection baselines.
Zero-shot Outlier Detection via Prior-data Fitted Networks: Model Selection Bygone!
Sep 09, 2024Outlier detection (OD) has a vast literature as it finds numerous applications in environmental monitoring, cybersecurity, finance, and medicine to name a few. Being an inherently unsupervised task, model selection is a key bottleneck for OD (both algorithm and hyperparameter selection) without label supervision. There is a long list of techniques to choose from -- both classical algorithms and deep neural architectures -- and while several studies report their hyperparameter sensitivity, the literature is quite slim on unsupervised model selection -- limiting the effective use of OD in practice. In this paper we present FoMo-0D, for zero/0-shot OD exploring a transformative new direction that bypasses the hurdle of model selection altogether (!), thus breaking new ground. The fundamental idea behind FoMo-0D is the Prior-data Fitted Networks, recently introduced by Muller et al.(2022), which trains a Transformer model on a large body of synthetically generated data from a prior data distribution. In essence, FoMo-0D is a pretrained Foundation Model for zero/0-shot OD on tabular data, which can directly predict the (outlier/inlier) label of any test data at inference time, by merely a single forward pass -- making obsolete the need for choosing an algorithm/architecture, tuning its associated hyperparameters, and even training any model parameters when given a new OD dataset. Extensive experiments on 57 public benchmark datasets against 26 baseline methods show that FoMo-0D performs statistically no different from the top 2nd baseline, while significantly outperforming the majority of the baselines, with an average inference time of 7.7 ms per test sample.
Outlier Detection Bias Busted: Understanding Sources of Algorithmic Bias through Data-centric Factors
Aug 24, 2024



The astonishing successes of ML have raised growing concern for the fairness of modern methods when deployed in real world settings. However, studies on fairness have mostly focused on supervised ML, while unsupervised outlier detection (OD), with numerous applications in finance, security, etc., have attracted little attention. While a few studies proposed fairness-enhanced OD algorithms, they remain agnostic to the underlying driving mechanisms or sources of unfairness. Even within the supervised ML literature, there exists debate on whether unfairness stems solely from algorithmic biases (i.e. design choices) or from the biases encoded in the data on which they are trained. To close this gap, this work aims to shed light on the possible sources of unfairness in OD by auditing detection models under different data-centric factors. By injecting various known biases into the input data -- as pertain to sample size disparity, under-representation, feature measurement noise, and group membership obfuscation -- we find that the OD algorithms under the study all exhibit fairness pitfalls, although differing in which types of data bias they are more susceptible to. Most notable of our study is to demonstrate that OD algorithm bias is not merely a data bias problem. A key realization is that the data properties that emerge from bias injection could as well be organic -- as pertain to natural group differences w.r.t. sparsity, base rate, variance, and multi-modality. Either natural or biased, such data properties can give rise to unfairness as they interact with certain algorithmic design choices.